Fun with BPMN and DMN: The Book Raffle

At a recent event, I had the pleasure of being able to give away a couple of books to a group of attendees. The group was about 8 people and there were 2 different books. Now the easy way to handle the situation would have been to put name cards in a container and do a blind pick for each book. But there’s no fun in that, is there? Since this event was all about BPMN and DMN, the ISO standards for process modelling and decision modelling, respectively, it was an ideal opportunity to show how versatile the application of both is. So instead of drawing straws to gift the books, we powered our little raffle by process and decision models, all executed in Camunda’s SaaS offering.
Because we can. Because we want to. But mostly because it’s fun while illustrating a point. Let’s have a look at how.
The Set Up
There are two main parts to this raffle: running the raffle itself and drawing names for both of the giveaway books. If you think about it, the first part can be captured by a really simple process model that coordinates two decisions: decide who wins book 1 and who wins book 2.
Such a model might look like this.
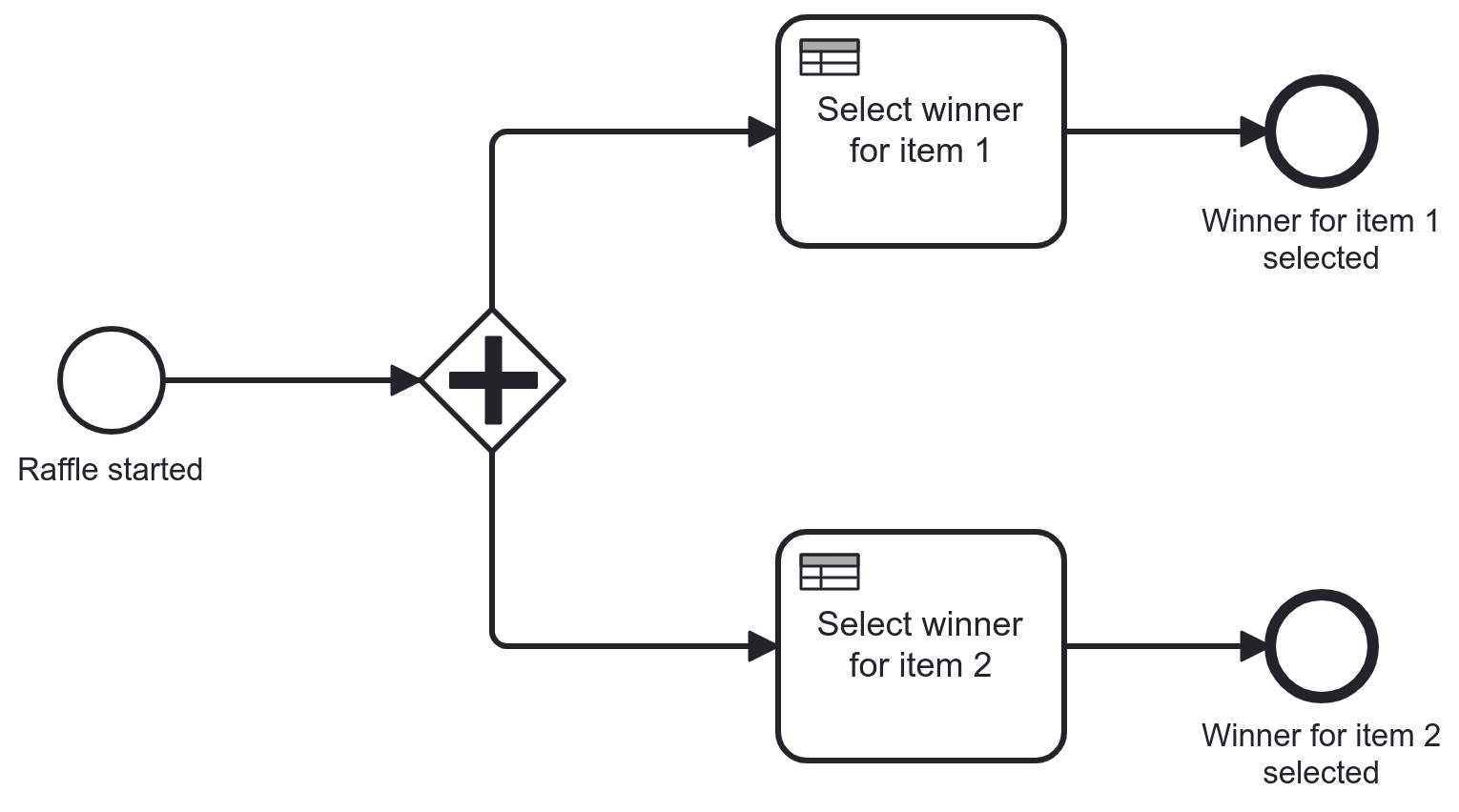
Hardly a spectacular use of BPMN to orchestrate two tasks in parallel. In fact, if it weren’t for two additional factors, it would likely not have warranted a blog post. What makes things more interesting, then?
-
The raffle is weighted.
-
Raffles are supposed to have some element of chance to them.
As mentioned before, there are 2 books to divvy up between 8 people who have been learning about BPMN and DMN. Since people will have their personal preferences, one book is about BPMN and the other has to do with DMN. Each raffle participant receives not just one, but 3 raffle "tickets" and can place their bets strategically to skew the chances towards the book(s) they prefer. When deciding on each book, the weight of each participant’s preferences needs to be taken into account.
DMN may be cunningly designed to model and execute decision logic in a lot of different scenarios, but chance or randomness are not the kind of functions people had in mind when creating the standard. Decision logic for managed decisions tends to be deterministic, not coincidental. Fortunately, for our raffle, Camunda has something in store for us.
The Models
The initial process model as shown above should be a good starting point. Once started, we decide for both books who the winner is, after which the process is completed. We’ll shift our focus to the decision itself for now.
The requirements for the decision are straightforward. Our root decision is the winner of a single book and gets executed twice; once for each book. Based on the book and a random seed, we’ll select a winner.
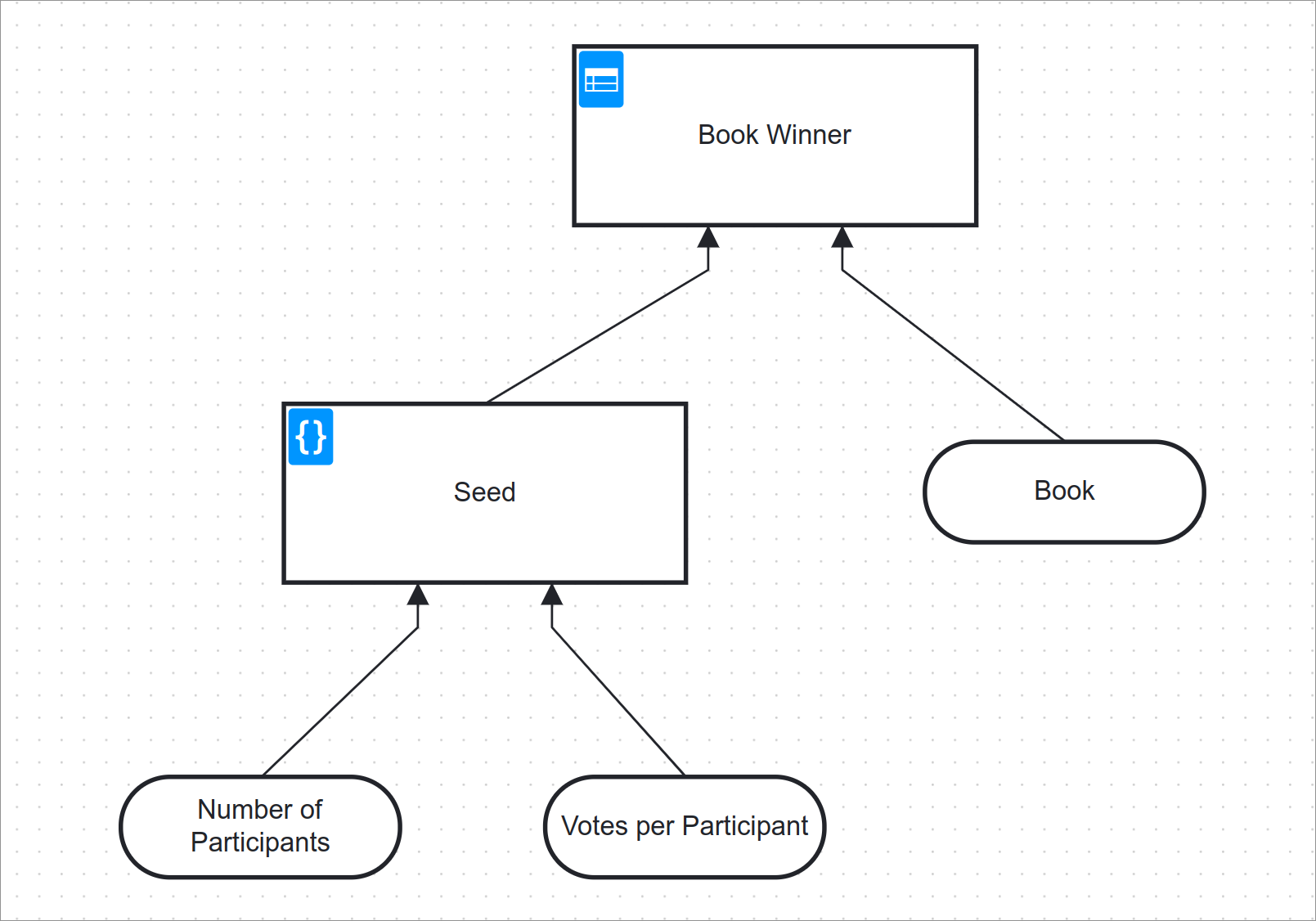
The Implementation
The decision logic for the Book Winner decision is - in this case - defined by a decision table. The table has inputs for the seed and the book and outputs for the lucky winner. The seed is simply a number. The idea behind the logic is that we will draw a random number and match it to a rule in the table. Each rule represents a "vote cast" by a participant, for a particular book.
Entering all of the rules during the event would be tedious and time consuming. To speed things up a little bit, the rules of the table are pre-populated. We initially add 6 rules for each participant, three for each book. Each rule corresponds to a seed number, the book and the participant. When participants tell us their preferences, we remove three of their rules, corresponding to the inverse of their preferences.
Randomness
In our implementation, we could have relied on some programming or scripting logic to draw a random number.
However, as it turns out, Camunda’s FEEL expression language, which is implemented in Scala, provides an extension method to the standardised methods of FEEL itself.
This is not just useful because it saves us from implementing code for the single number we need, but it also allows us to keep all of the decision logic in the DMN model.
The random number() function returns a random number from 0 to 1 and is exposed to literal expressions, such as our supporting decision for the seed.
The following expression in the Seed decision therefore allows us to draw a random number, spanning the range of possible numbers given the number of raffle participants and votes each participants has:
round half up((random number() * Number_of_Participants * Votes_per_Participant),0)The round half up function simply rounds the result up if the remainder is over .5.
This is used to make sure we end up with an integer, to match the numbers in the rows.
Gaps
Our current models should allow us to start a new raffle process, decide who wins each of the books and complete the process. However, there is a gap in the implementation. It’s actually a literal gap.
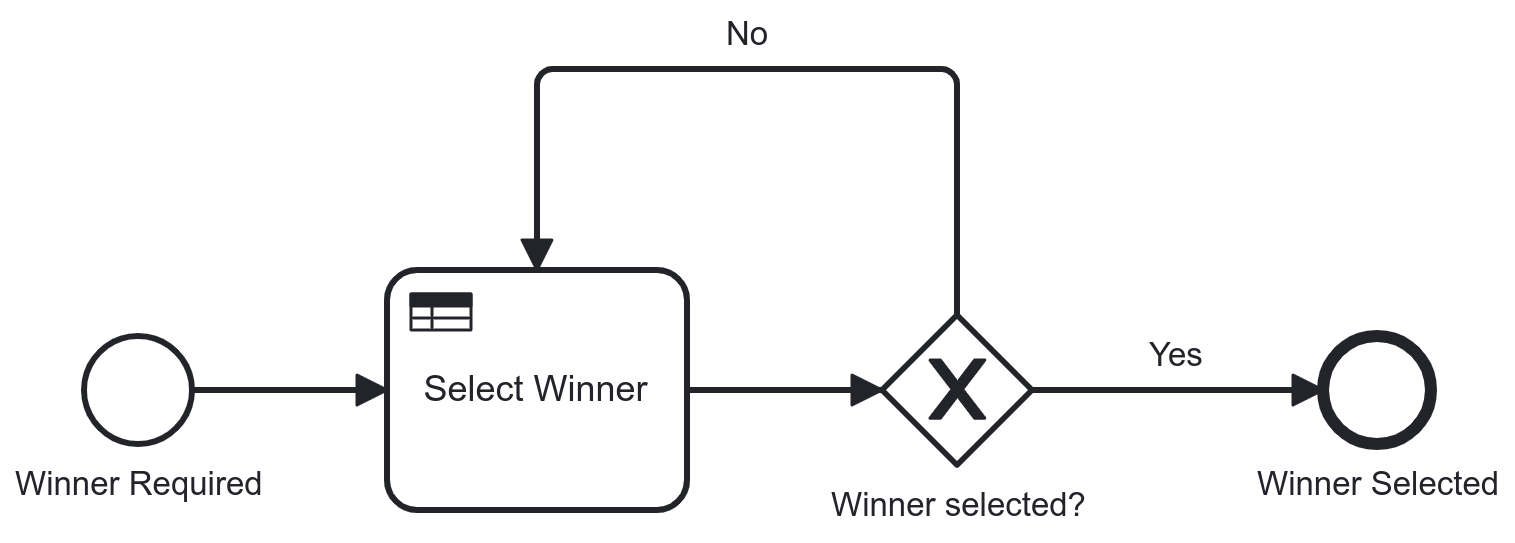
To understand why there is a gap in our logic, let’s look at the decision logic for the Book Winner decision.
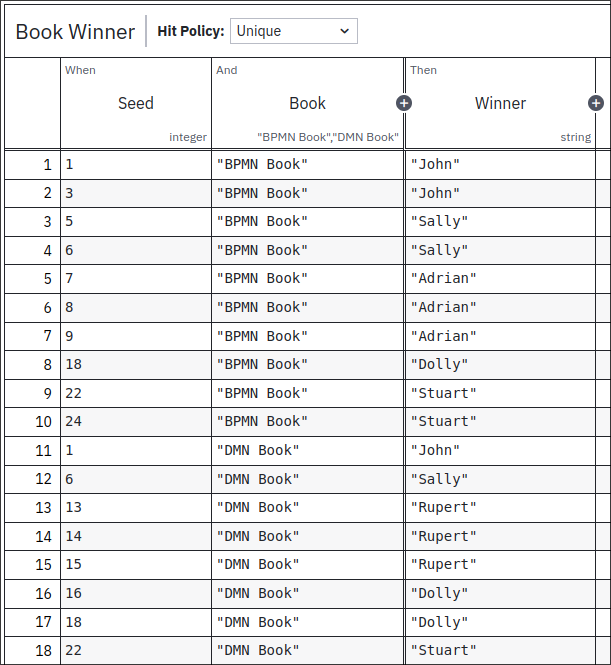
Because we removed the rows corresponding to the votes the participants did not cast, leaving their votes as the remaining rows in the table, there are gaps in the seed numbers that actually match a row for each book.
In the example, since John cast 2 votes for the BPMN book and only one for the DMN book, there is no row matching the seed 2 for the BPMN book.
Neither is there a 2 or 3 for the DMN book.
Those were John’s other three possible tickets that are no longer in the raffle.
Of course, we could solve this in multiple ways. For instance, we could re-number the rows to ensure a continuous range. That would be a lot of work to do on the spot and would require changing the logic of the Seed decision for each run.
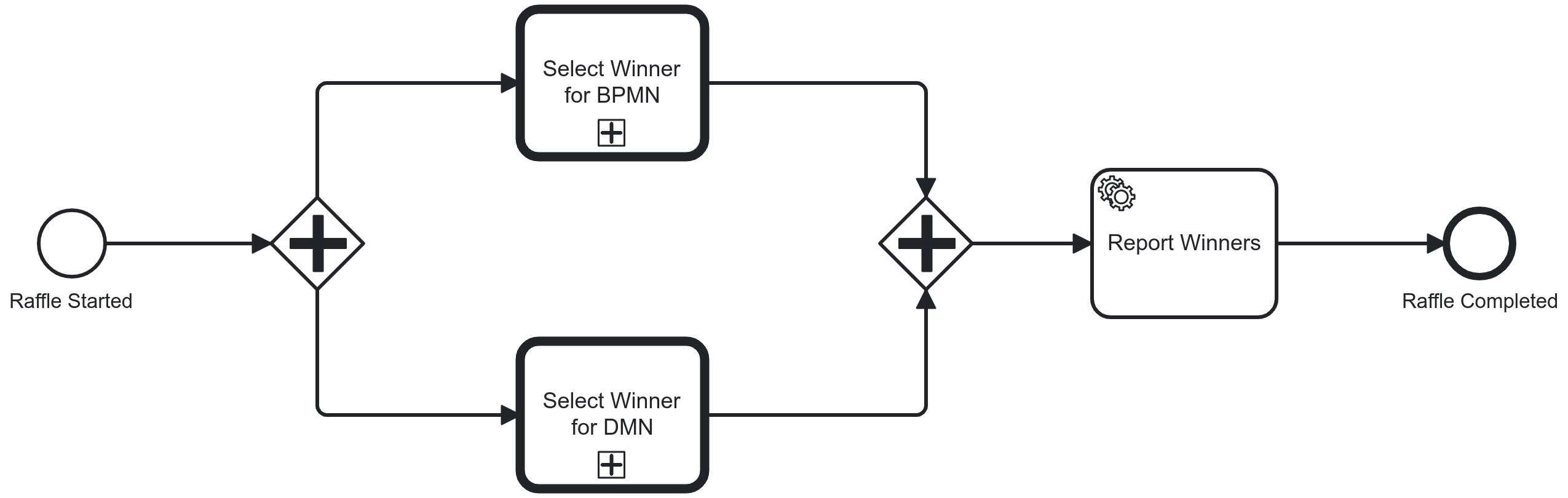
Instead, for a simple case like this, let’s brute force the decision until we have a winner for each book. If we update the process model as displayed below, we will likely have a winner within a split second too. We run a sub process for each of the books and in the sub process, we keep executing the decision until a winner is selected.
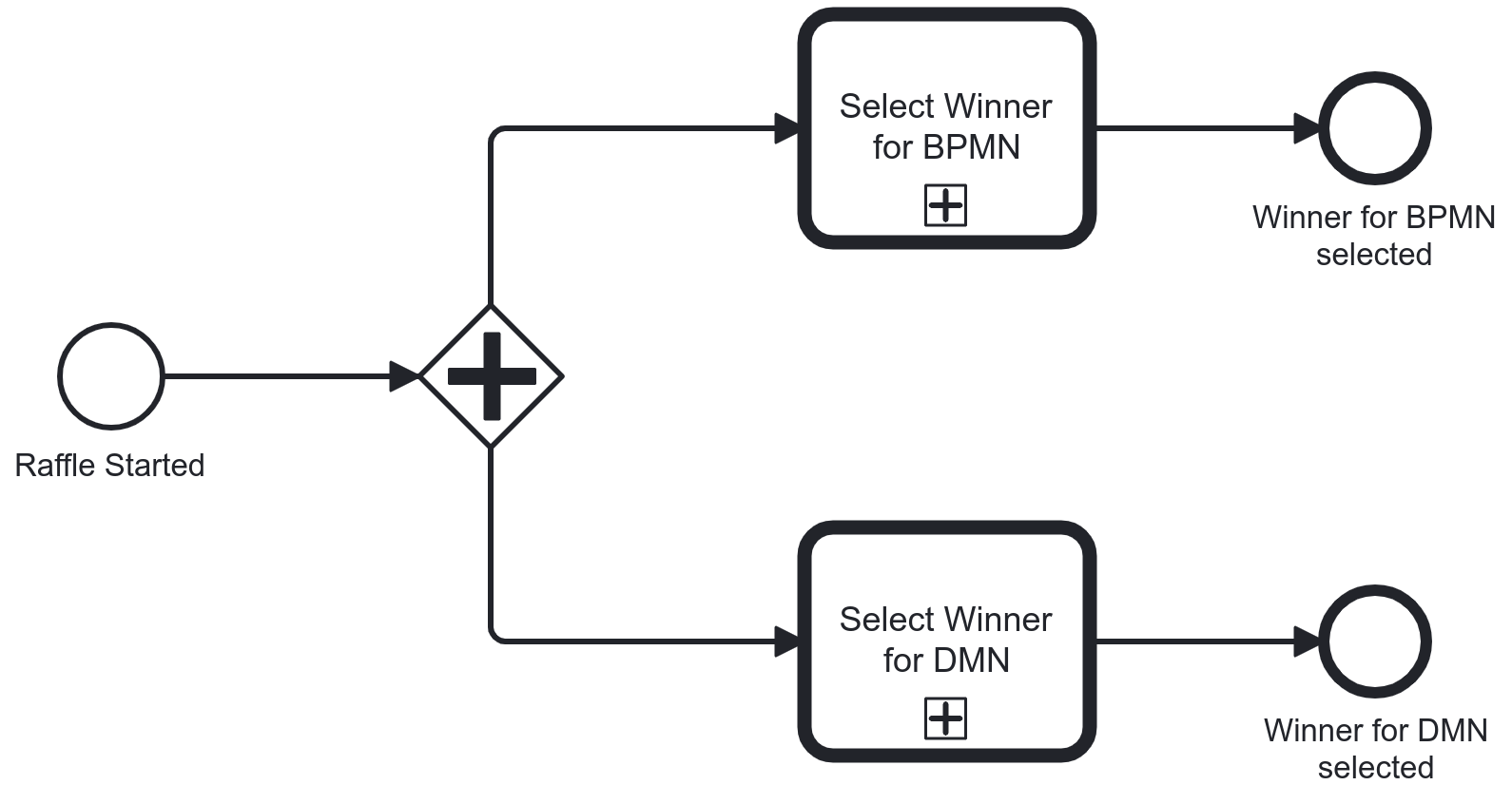
Party
This experiment was all about fun, so let’s add a final touch to our solution. We’ll add a service task after both books have been awarded and implement the simplest of job workers to display the outcome. After all, who needs a console to look up the outcome of a process, when you can use an API?
Our worker implementation runs in Node and looks like this.
const { ZBClient } = require('zeebe-node')
void (async () => {
const zbc = new ZBClient()
console.log("DRUM ROLL... Can you FEEL the suspense?...")
const zbWorker = zbc.createWorker({
taskType: 'raffle.winners',
taskHandler: handler,
})
function handler(job) {
const { winnerBPMN, winnerDMN } = job.variables
console.log('WE HAVE A WINNER FOR BPMN! Congratulations to... ' + winnerBPMN)
console.log('WE HAVE A WINNER FOR DMN! Congratulations to... ' + winnerDMN)
const updateToBrokerVariables = {
congratulated: true,
}
return job.complete(updateToBrokerVariables)
}
})()After each raffle has selected a winner for each book, the winners are reported in the console log.