The Embedded Engine

I had a lot of fun discussing the benefits of embedded process engines on a recent episode of Camunda Question Corner. Even though every approach has its pros and cons, embedding a process engine enables you to do some things that make it a very enticing option. This post explores some of these.
What do we mean by embedded process engine? An embedded process engine is a process engine that is added to another software application in order to equip that application with process automation capabilities. As obvious as that sounds, this is not a trivial feat. Many process execution solutions are not designed to become a part of another application in an unobtrusive way, for instance as a simple library. Rather, a more conventional approach is to have a standalone product that other applications need to integrate with to get things done and execute processes in the way that product expects. But let’s not dwell on the past, but look to the future :)
So what is it that an embedded process engine brings to the table?
State and Process Management
The most obvious capability that an embedded process engine adds to your application, is that of state management. Combined with the feature to interpret and execute process and decision models, it offers process management as an extension to that.
A lot of applications need to maintain state and there are plenty of options to implement it. What’s so special about this one? Well, making a piece of state persistent is, indeed, taken care of by many tools and these are readily available to developers. But that’s literally just the state. It doesn’t offer you anything more than the capability to make some data persistent. A process engine on the other hand implements defined ways of reaching and manipulating a certain state by executing predefined patterns. This is where the engine shines: you can model a process or declare a decision using a recognised standard (and the industry standards at the moment are BPMN, CMMN and DMN) and the state will be managed in a predictable way based on your model.

Many applications start by adding this state management by themselves. Often, the first thought is: "hoe hard can it be? We persist state all the time.". Then, as the application develops, so do its requirements and new things start showing up that require some kind of state or process management.
"If we try to file this document with the third-party vendor and it fails, which we know it will from time to time, we need to keep trying every 5 minutes for at least 10 times before reporting a permanent failure."
"If the customer cancels before the final phase, we should revert the reservation made and wait for a confirmation of the cancellation from the supplier. But only if the reservation, which is optional, was made."
"Any request over 50 items must go through the appropriate account manager, who has 5 days to approve, after which there is an algorithm to determine the priority."
All these are typical requirements for a business process and require persistent state of the point of the current execution, its history and future options. They involve scheduling, waiting, routing, automated processing and retrying, to name but a few. You could program these yourself, but a ready made component that allows you to simply declare them in a model is the better choice for spending your development and maintenance budget and lets you focus on your actual business logic that gives you a competitive advantage.
With the process engine embedded in your application, it gains all of these functions in one fell swoop. You can schedule tasks for the future, have them repeat, respond to external signals, create work to be executed manually by users, execute decisions, all without any effort to make such things possible. Because these options are now a part of the application, the processes and decisions become a natural part of the application. The application may already have been responsible for this (part of the) process, so why not make it official and add the process and decision models to the deployment of the application itself? With an embedded engine, you can simplify your deployment.
You can integrate the code for the process easily with the process execution - no remote calls between systems to execute a task. From the process, you can directly access the application’s data too, when needed. Authorisations can be local to the application instead of distributed, keeping the landscape simple.
Even with all that functionality packed into the application, you can still scale the application by running multiple instances of it. Your process engine will scale along with the application and coordinate the work going on, even between the instances. This has limits of course, but most of them come down to what your database can handle, eventually.
The application can now manage the state and processes as a local concern. At the same time, this application has gained options even beyond executing processes and decisions: it has become manageable for those executions. The process engine comes with ways to observe the progress and failures of ongoing work. The performance can be measured and monitored for both analytical and operational purposes. You can report on process and decision execution and when things go wrong, there are options to intervene to get things back on track. If you embed the process engine, all of these can be applied and tuned to the specifics of your application.
Imagine to building, testing, extending, documenting and maintaining all of these things yourself and it becomes clear why general purpose process engines exist and why an engine that can be embedded into your application is a powerful tool.

By embedding the process engine that comes with so many features, you’ve instantly gained them for your application, without having to change much of your application (in most cases). Your deployment has not become more complex, nor have you added yet another component in the landscape that suffers the downsides and pitfalls of a distributed system.
Towards Contexts
Talking of distributed systems, you might wonder: aren’t a lot of applications moving in precisely the opposite direction? Instead of internalising all of the things an application might have to do, many systems are already evolving towards a distributed architecture and following the Bounded Context approach from Domain Driven Design.
Adding a process engine to your application can be a perfect fit for those applications, too. You can even add one to each application or context you have if it needs state and process management. The local capability of executing processes and decisions is a good start. Within the application, the process and decision logic is nicely separated from the rest of the business logic, to make it manageable and to allow it to evolve without too much entanglement getting in the way.
In a micro services system landscape, each application may not implement a complete business process end to end all by itself. However, it is still responsible for part of a process, participates by providing a sub process to some others or coordinates the work that is comprised of executions in other applications. It still needs the state management and the workflow and decision patterns, but focussed on its own specific part(s). Other applications have the same need for their share of the process(es).
Now you could centralise the process coordination in a single application. The downside to this is that the autonomy for each of the applications decreases as they all become dependent on one central component, just to gain state management and even if their work only requires internal coordination. The inevitable questions for such an architecture also come up: who maintains this central process capability, used by all? Who dares to upgrade it to a newer version, potentially affecting dozens or even hundreds of other components? Who tests all of the process interactions for these centrally managed models?
Besides the maintenance questions, there is an optimisation issue with the centralised model. Processes, especially those spanning multiple business capabilities (as is common in micro services, by dividing by business functions), tend to be very different in nature. This is true in functional terms, but as a result most certainly also applies to their technical support when automated. Your once-a-quarter reporting and review process is very different from the monthly invoice run. The shared process execution can only be optimised to serve all of these different processes at a reasonable level.
Now that (parts of) these processes are allocated to separate applications in your contexts, you want to optimise for their individual workload. With an embedded engine in these applications, you can. The engine for the reporting process is configured differently than the high-volume invoicing application.
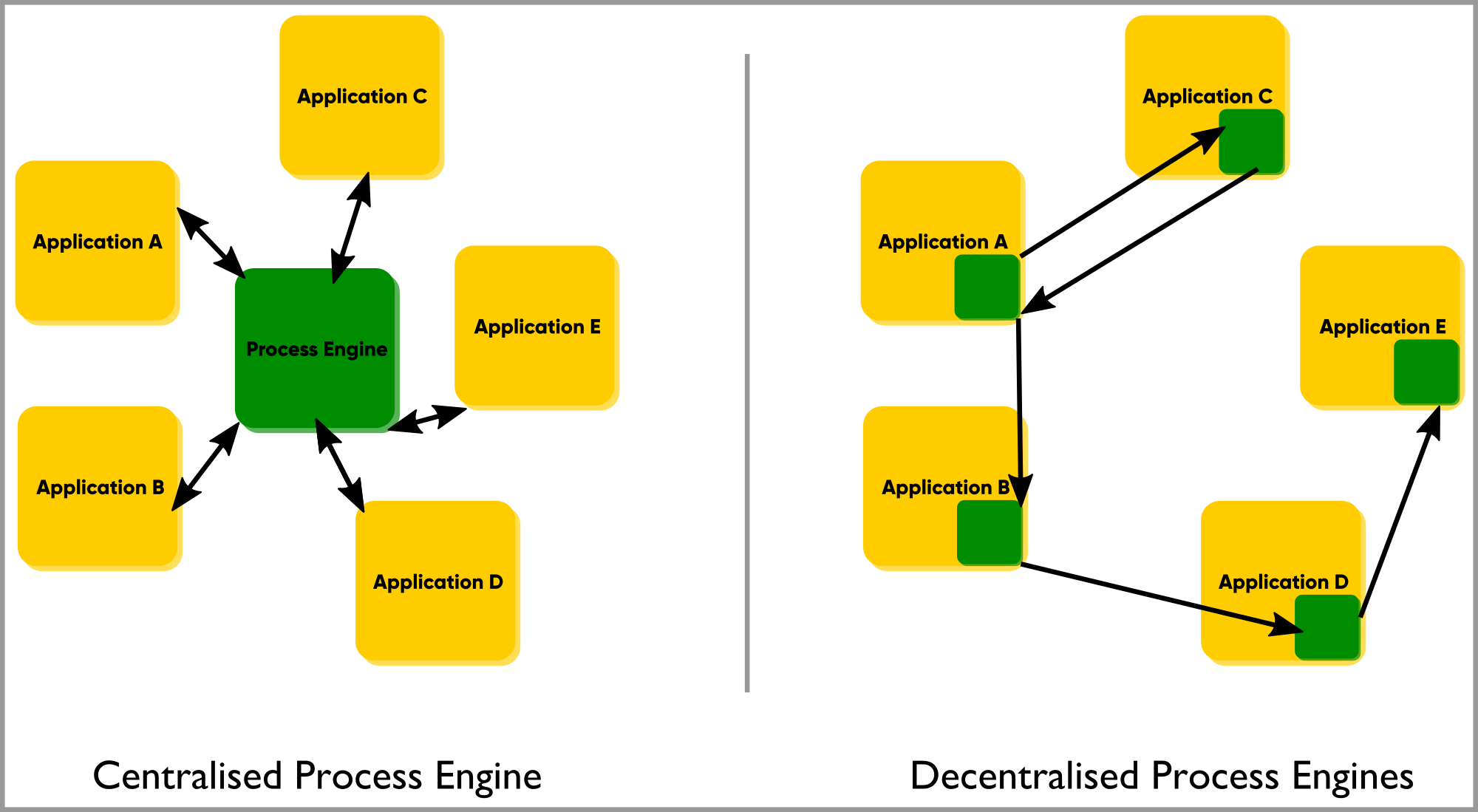
When processes collaborate, there are relationships between them. Some are upstream processes, others are downstream. Your distributed micro services landscape with embedded process engines allows you to create highly optimised and isolated services that have the patterns built in to collaborate according to their contexts' relationships. This is sometimes referred to as local orchestration, global choreography. You don’t have to choose one or the other; the mix you end up with and that continues to evolve is the result of a deliberate design effort, tailored to the specifics of your processes and decisions.
Transactional Integration
Even after all of these advantages, there’s a technical benefit that hasn’t been mentioned yet, but really deserves a separate mention: transactional integration. That sounds like a mouthful, but in simple terms it means: your process state, your process and decision data and your application data are always in sync.
By embedding the process engine in the application, it is possible to integrate the transactions that persist the application data (your invoices, your client accounts, anything your application is in charge of safekeeping) and those of the process engine. There are some technicalities that limit this, but in general it is far easier to integrate the transactions inside the application than between separate components.
Without this integration, when technical exceptions occur (and as we all know, they will), the state of the application and the process may become disconnected. For instance, the process might consider a task completed, whereas the information that was stored during the task has not been saved. Conversely, some change to the application’s data may have been effected, but the process is expecting the step that modifies the data to take place (again).

These kinds of problems can easily occur and can be hard or costly to recover from. An embedded process engine can help to prevent most of these issues by making sure either all of the state is saved, or none is saved and can be attempted again. The process and application are always in sync and consistent.
Extending Behaviour
Feature-packed as your process engine might be, your application may have specific requirements the engine doesn’t offer out of the box. At the same time, it likely has some degree of extensibility built-in which you can leverage. Most of the extension points require hooking in to the existing functionality of your engine and adding your own custom logic or even swapping a complete part of the engine’s default behaviour with your own. An embedded engine allows you to add your customisations directly from the application that needs them. Additionally, your extensions can integrate with your application’s logic, data and transactions.
In the case of Camunda, this is offered in the form of interfaces you can implement in Java and implementations you can swap by using configuration.
You can add TaskListeners, ExecutionListeners, swap ActivityBehaviors and use ParseListeners to hook into model parsing.
And when it comes to chaining some functionality offered by your process engine’s APIs, you can program that logic right where you need it instead of coordinating a whole slew of REST calls.
If you have some special requirement, the tools to latch on to all the functionality that’s already there is at your fingertips from the application itself.
Wrapping Up
You can gain a lot from embedding a process engine in your application. Orchestrating and choreographing process and decisions allows you to focus on the business logic of the application instead of the plumbing. You get to follow, operate and report on the engine’s execution straight out of the box and optimise its performance for your application. Your data and the process state are always aligned, even when you decide to extend the functionality of the engine.
Check out the Question Corner Recording or get in touch if you’d like to discuss embedded process engines!